Introduction
One of the fundamental data structures in Python is the list. Often,
we create lists based on existing lists, or based on some iterated
values. In many of these cases, it is natural to use a for loop to create
the list.
For example, suppose we are studying the quality of a pseudo-random number
generator (PRNG). To do that, we require large quantities of numbers produced by
the PRNG, which we will pass through a series of statistical tests to determine
if the PRNG produces numbers that are “random” enough. We could prepare for
the statistical work by creating a large Python list of pseudo-random numbers.
The straightforward approach to this task is to create and empty list, and then
use a for loop to populate the list, as shown in the following code:
1
2
3
4
5
6
7
# Sample 1: Building a list with a for loop
# n contains number of values to create
import random
values = []
for i in range(n): # part a
values.append(random.random()) # part b
Simple list comprehension
Python provides a mechanism for creating lists, called list comprehension,
that can be used in many instances where we might normally use a for loop.
List comprehension is significantly faster than the equivalent for loop
code. There are several, successively more complicated ways to use list
comprehension, but the efficiency-boosting advice of this page is: if you
are using a loop to build a list, see if you can use list comprehension
instead.
Tip: If possible, build lists with list comprehension instead of loops.
In the random-list-building code above, we have the for loop first
(line 4, labeled as part a), and the expression producing each
number that is appended to the list second (in line 5, labeled as
part b). List comprehension turns the order of those two elements around,
as shown here:
[<expression> for <v1> in <seq1>]
Here, <expression> corresponds to part b, while for <v1> in <seq1>
corresponds to part a. Essentially, the body of the for loop is
specified first, and the for loop information itself is specified
second.
In our list comprehension syntax, <expression> may be any valid
Python expression. The angle brackets (< >) are not part of the
expression; instead, they mean that <expression> is to be replaced by
some valid Python expression. Similarly, <v1> is the for loop
variable, and <seq1> is the Python sequence to iterate over.
The <expression> may depend somehow on the loop variable <v1>,
but that is not required.
Using list comprehension, we can create a list of random values
in a single line of Python code, rather than the three lines required
in the for loop version, and our code will be faster than the
for loop version. Here is the equivalent code using list comprehension:
1
2
3
4
5
# Sample 2: building a similar list with comprehension
# n contains number of values to create
import random
values = [random.random() for i in range(n)]
Line 5 of this code does all the work. Here, random.random() is the
<expression>, a.k.a. part b, i is <v1>, and range(n)
is <seq1>. Note that in this case, the expression random.random()
does not depend at all on the loop variable i.
To illustrate the performance improvement obtained through list comprehension,
we executed Sample 1 and Sample 2 for values of n ranging from
1,000,000 to 100,000,000 in increments of 1,000,000, and recorded the runtimes
for each trial.
Here is a plot showing the runtimes from our trials, as well as the speedup for each.
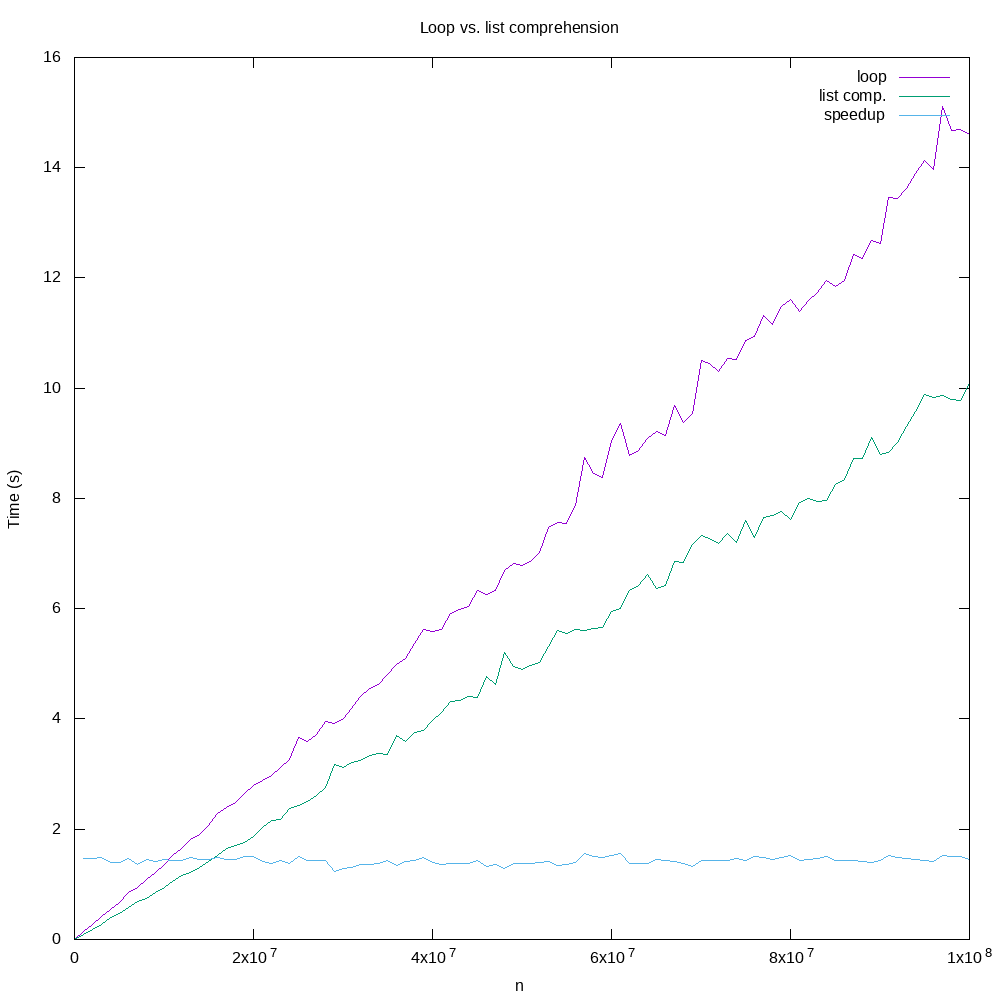
It is clear from the plot that list comprehension is significantly faster
than creating the list via a for loop! We have a roughly constant speedup of
approximately 1.5 for each of the cases.
Tip: If you participate in programming competitions, list comprehension
can be a great way to get all of the numbers on an input line in a single
list, with only one line of code, like this: nums = [int(x) for x in input().split()].
List comprehension with an if
We can also use an if statement in list comprehension, to filter the elements
that appear in the new list. Suppose, for example, that we have a large list of
correctly-spelled English words, and that we wish to make a new list containing
only the words that start with ‘Q’. Maybe we are trying to maximize our score
in a Scrabble game!
Sample 3 is loop-based code to solve this problem. The new wrinkle here
compared to Sample 1 is that we have an if statement in the loop
that only adds the words starting with ‘Q’ to the list named dict.
Like we did for Sample 1, we have labeled the three important parts of the
code: the loop is part a, the if statement is part b, and adding
to the list is done in part c.
1
2
3
4
5
6
7
8
9
10
11
# Sample 3: filtering words
with open('dictionary.txt', 'r') as inFile:
dict = [word[:-1] for word in inFile]
Qs = []
# make a sublist of only words that start with 'Q'
for word in dict: # part a
if word[0] == 'Q': # part b
Qs.append(word) # part c
print(Qs)
When executed, the code behaves as we expect, with output that looks like this:
['Q', "Q'S", 'QA', 'QADDAFI', ... 'QUOTING', 'QWERTY', 'QWERTYS']
To use the if version of list comprehension, we use this syntax:
[<expression> for <v1> in <seq1> if <condition>]
In this syntax, <expression> corresponds to part c of Sample 3,
the for loop corresponds to part a, and the if statement
corresponds to part b.
Sample 4 shows how we can build the same list in one line of Python
code, using list comprehension with an if.
1
2
3
4
5
6
7
8
# Sample 4: filtering words with list comprehension
with open('dictionary.txt', 'r') as inFile:
dict = [word[:-1] for word in inFile]
# make a sublist of only words that start with 'Q'
Qs = [word for word in dict if word[0] == 'Q']
print(Qs)
This creates an identical list as Sample 3, and is significantly faster. On our test system, creating the ‘Q’ word list with comprehension provided a speedup of 1.32, compared to the for loop version.
List comprehension with multiple fors
It is also possible to use multiple for statements in a list comprehension.
Then syntax for list comprehension syntax with multiple fors is:
[<expression> for <v1> in <seq1>
for <v2> in <seq2>
for <v3> in <seq3>
...
if <condition>]
We can have as many for portions as we wish, but only one if. To illustrate
how this type of list comprehension works, consider this example, which creates
a list of two-element tuples, based on two existing lists:
1
2
3
4
5
6
7
8
9
10
# Sample 5: creating list of tuples with loops
letters = ['a', 'b', 'c', 'd']
digits = [1, 2, 3]
values = []
for x in letters:
for y in digits:
values.append((x, y))
print(values)
This code produces all of the possible tuples of the form (c, d), where c is a character from {‘a’, ‘b’, ‘c’, ‘d’} and d is a digit from {1, 2, 3}, as seen in its output:
[('a', 1), ('a', 2), ('a', 3), ('b', 1), ('b', 2), ('b', 3), ('c', 1), ('c', 2), ('c', 3), ('d', 1), ('d', 2), ('d', 3)]
We can create the same list of tuples via a list comprehension that uses two for statements,
as shown in Sample 6.
1
2
3
4
5
# Sample 6: creating list of tuples with comprehension
letters = ['a', 'b', 'c', 'd']
digits = [1, 2, 3]
values = [(x, y) for x in letters for y in digits]
Now that you have learned about list comprehension, test your understanding through the following exercises.
Exercise 1
The code shown below creates a large list of pseudo-random
numbers in [0, 100000), then uses a for loop to create a new list
containing only the even values. Re-write this code to use list
comprehension to create the evenValues list.
1
2
3
4
5
6
7
8
# list creation
rawValues = [random.randrange(0, 100000) for i in range(100000000)]
# loop version
evenValues = []
for v in rawValues:
if v % 2 == 0:
evenValues.append(v)
Exericse 2
Let us return to the idea of testing the quality of a PRNG. The code
below is a fragment that ultimately will print out the number of times
each of the numbers in [1, 10] occurs in a sequence of “randomly”
generated inteters. Finish the code using list comprehension – by
changing only the line indicated with the comment. In other words,
what you write has to be on the right side of the freq = assignment.
Hint: use list comprehension to build a list of 1’s, one for each
time i occurs in data, and pass that list to the built-in sum()
function.
1
2
3
4
5
6
7
8
9
import random
# create 100,000 randoms in [1, 10]
data = [random.randrange(1,11) for i in range(100000)]
# view frequency of each value
for i in range(1, 11):
freq = # replace this comment with your code
print('{0:3d}:\t{1:d}'.format(i, freq))
Your output might look like this:
1: 9987
2: 9940
3: 10037
4: 10028
5: 10002
6: 10088
7: 9838
8: 10002
9: 10028
10: 10050
Speedup
We refer to speedup as a way to compare our optimized code with its original, slower counterpart. Speedup is a measure of how well we have improved the runtime of our code. If T0 is the time taken by the original code, and T1 is the time taken by the improved code, then speedup is defined as
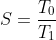
A speedup of 2 would mean that our optimized code is twice as fast as the original, while any value under 1 would mean that we actually made our code slower!
All performance figures on this page were obtained on a Windows 10 PC with an Intel® Core™ i5-9600K CPU @ 3.70GHz and 32GB of RAM, in Python 3.6.9 running in an Ubuntu Windows Subsystem for Linux environment.
Next lesson
The next lesson in the workshop is about using aliases